Godot Engineのカレンダー | Advent Calendar 2023 - Qiita の11日目の記事です。
◆前の日は@NumAniCloud さんのC#プロジェクトを分割して開発しよう、の話 です。
◆次の日はきゃべつ さんのGodot(C#)シーン派生とクラス派生 #C# - Qiita です。
現在、Godotへの移住を検討するために調査をしています。丁度、シェーダーの使い方を調べているところだったので、リアル「はじめてのGodotシェーダー」です。Godotの公式マニュアルには基礎から参考リンクまでばっちりまとまっています。
docs.godotengine.org
ただ動かすまでに少し手数がかかるので、Godotのインストールから簡単な2Dフラグメントシェーダーを作る流れをまとめました。GodotはノードベースのVisual Shaderも持っているのですが今回はコードで書きます。公式マニュアルの最初の2Dシェーダーの作り方を少しアレンジしたものと、The Book of Shaders に掲載されているサンプルコードをいくつか動かします。
Godotやシェーダーを使ったことがない人でも眺めてなんとなく雰囲気が伝わる記事を目指しました。
目次
バージョン
このブログ記事を書いた環境は以下の通りです。
対象読者
Godotにもシェーダーにも触れたことがない人でも動かすことはできると思います。
Godotとは
2Dも3Dもいけるオープンソース のゲームエンジン です。Win, Mac , Linux のデスクトップPCやAndroid とiOS 、WebGL 用のビルドもできます。Switchのようなコンソールへの出力は公式ではサポートしていませんが不可能ということではありません。コンソールの開発に必要な情報に守秘義務 があるためオープンソース のGodotに含めることができないということです。自力で対応したり、経験があるパブリッシャーを通せばリリースできます。※丁度この記事の公開日にW4 Games からGodotのプロジェクトをSwitchやXBox , PS5といったコンソールに出力するサービスの開始予定と価格についての発表 がありました!
開発言語はいくつか選択肢がありますがGDScriptという独自言語が推奨されています。インデントでコードのブロックを表すなどPython に雰囲気が似ています。C# もスクリプト として使えるように整備が進んでいますが、正式対応はデスクトップのみで4.2からiOS やAndroid でも実験的に動くようになりました、という段階です。
シェーダー言語はGLSLをベースにした独自のシェーダー言語とVisual Shaderが使えます。このブログではシェーダー言語でフラグメントシェーダーを書いてみます。
詳しくは公式ドキュメント をどうぞ。
Godotのインストール
Godotはオープンソース のゲームエンジン なので、管理者権限もインストールもアカウント作成も必要ありません。zipファイルをダウンロードして展開すればすぐに使えます。この手軽さは最高です!
godotengine.org
最新版のダウンロード
GDScriptを使う場合は上のGodot Engineをダウンロードします。C# を使う場合は下の.NET版をダウンロードします。今回はスクリプト には触れないのでどちらでも構いません
GDScriptを使う場合は上の方
寄付(Donation)画面を×をクリックして閉じます。儲かったらぜひ寄付してください
寄付画面を閉じる
ダウンロードしたzipファイルを任意の場所に移動して展開すれば完了です。フォルダーの中のGodot_v4.2-stable_win64.exeをダブルクリックすればエディターが起動します。
エディターを起動
プロジェクト作成
シェーダーを試すためのプロジェクトを作成します。
新規プロジェクトの作成
レンダラーはデスクトップ用のForward+を選んで、フォルダーを選ぶために参照ボタンをクリックします
フォルダーを選択
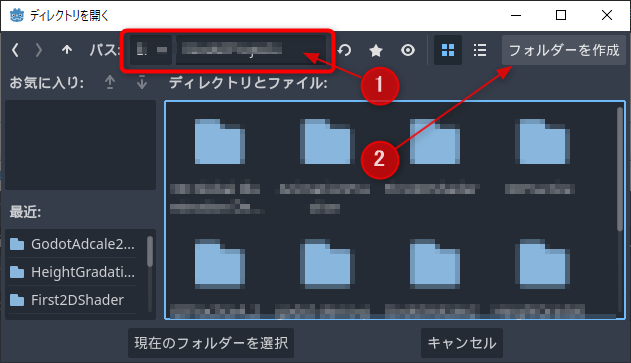
プロジェクトを作成したいフォルダーの位置を指定して、新しいフォルダーを作成します
プロジェクトの作成先を指定して、プロジェクト用のフォルダーを作成
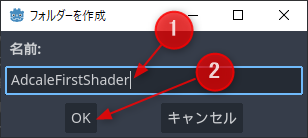
プロジェクト名のフォルダー名を入力します。以下はAdcaleFirstShaderとした例です
AdcaleFirstShaderという名前でフォルダーを作成
フォルダーを作成したら、現在のフォルダーを選択をクリックします
プロジェクトを作成
以上で新規のプロジェクトが作成できます。
新規プロジェクトの作成完了
※Godotは動作がまあまあ不安定で、まあまあいきなり落ちます。適度に保存をしながら作業を進めてください。特に間違った操作をしていなくても落ちるときがあるので、落ちても気にしないで起動し直して作業を継続して大丈夫です。
はじめてのシェーダープログラミング
細かいことはあとにして動かしてみます。シェーダーにはいくつか種類があります。はじめての今回は効果が分かりやすいフラグメントシェーダーを使ってみます。
シェーダーの描画先をColorRectで作成
フラグメント(=fragment)は断片というような意味です。フラグメントシェーダーは対象となる図形のピクセル の色を設定するためのプログラムです。塗りつぶす範囲を表す図形とシェーダープログラムを設定するマテリアルが必要です。まずはシンプルに2Dで試してみます。
シーンの+をクリックして、検索欄にcolorと入力します。ColorRectが見つかったら選択して、作成ボタンをクリックします
ColorRectを作成
ColorRectを画面いっぱいに設定します。インスペクターのLayoutをクリックして開いて、Anchors Preset欄をクリックしてRect全面を選択します
ColorRectを画面全体に設定
Ctrl+Sキーを押して保存します。ファイル名はそのままでも構いませんし、first_2d_shader.tscnなどにしてもよいでしょう
シーンを保存
実行してみます。F6キーを押すか、現在のシーンを実行ボタンをクリックします
現在のシーンを実行
成功するとGodotのロゴが表示されたあとに真っ白なウィンドウが表示されます。
画面が真っ白になればOK
確認したらウィンドウを閉じます。
これでフラグメントシェーダーで描画する先ができました!
はじめてのシェーダープログラミング
シェーダープログラムはマテリアルに設定します。そのためのマテリアルを作成します。
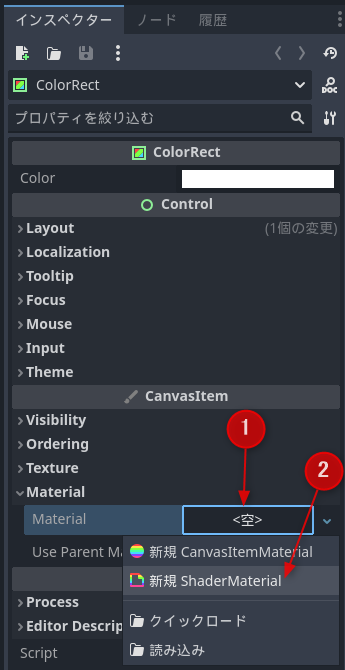
インスペクターのCanvasItem欄のMaterialの横の空欄をクリックして、新規ShaderMaterialを選択します
新規ShaderMaterialを作成
Material欄にあらわれた球体をクリックして、Shader欄の空欄をクリックして、新しいシェーダーをクリックします
新しいシェーダーを作成
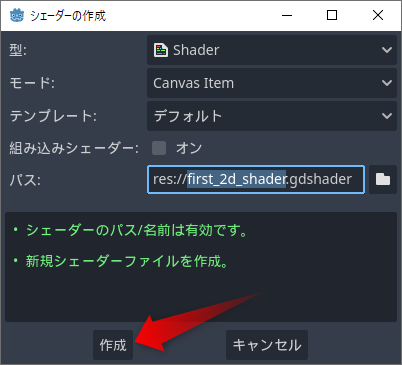
作成ボタンを押して、デフォルトのままCanvasItemのシェーダーを作成します
シェーダーを作成
シェーダースクリプト のファイルを開く
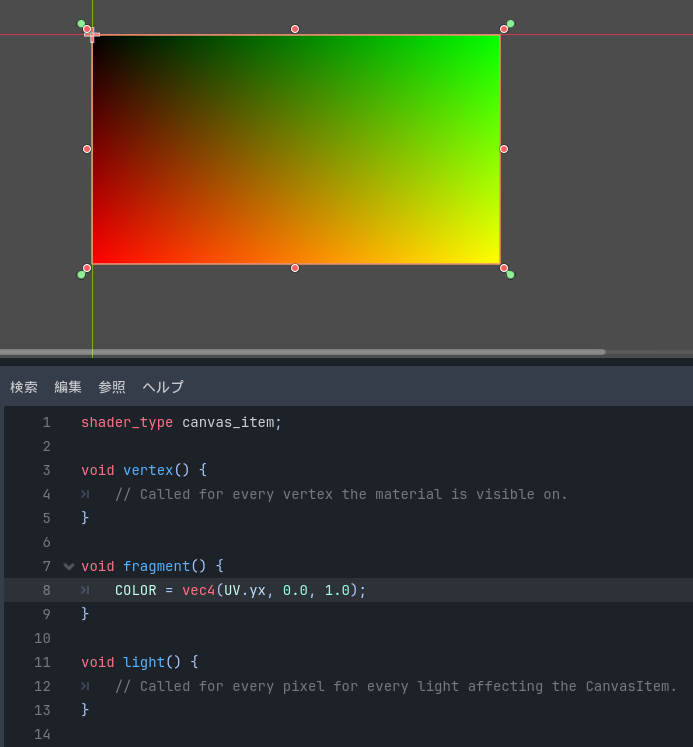
以上でシェーダーエディターに切り替わって、デフォルトのCanvasItemシェーダーが表示されます。最初は以下のようになっています。
shader_type canvas_item;
void vertex() {
}
void fragment() {
}
void light() {
}
3つの空のメソッドが用意されています。それぞれ次のようなコメントが書かれています。
vertex()
表示されているマテリアルの頂点ごとに呼び出されます
fragment()
表示されているマテリアルのピクセル ごとに呼び出されます
light()
CanvasItemに影響を与えるすべてのライトごとに、すべてのピクセル に対して呼び出されます
今回利用するのはフラグメントシェーダーです。void fragment()からはじまる部分を次のように変更してください。途中でエラーが表示されても構わずすべて入力を終えて下さい。
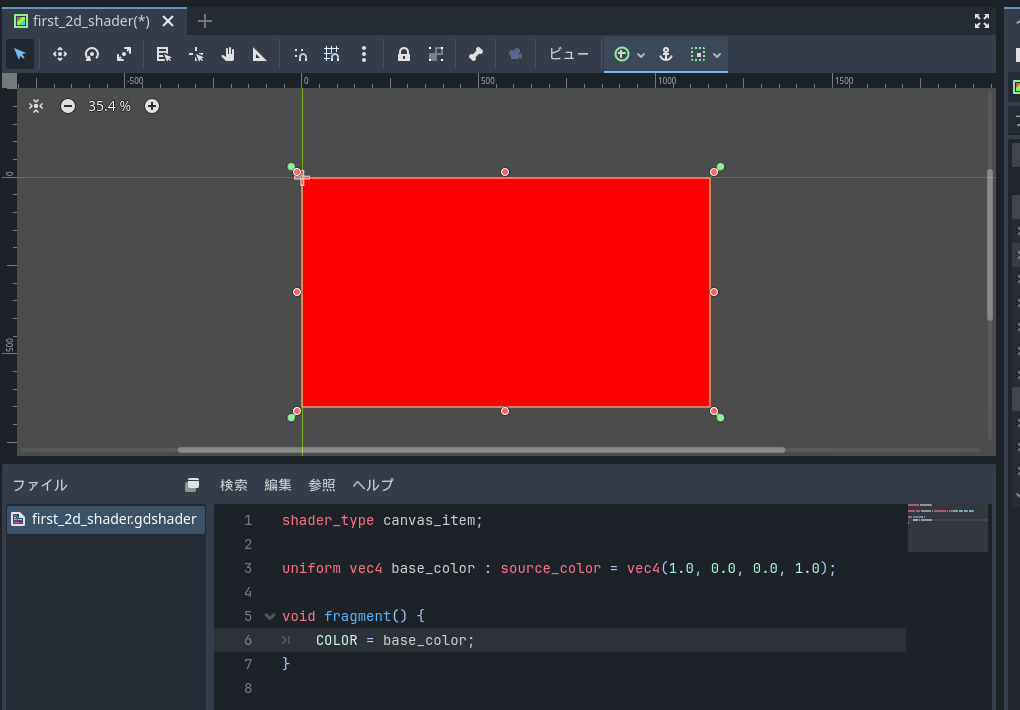
void fragment() {
COLOR = vec4(1.0 , 0.0 , 0.0 , 1.0 );
}
入力が終わってしばらく待つか、Ctrl+Sキーで保存すると白かったColorRectが赤くなります。
赤くなれば成功!
最初のシェーダーが完成しました!!
F6キーや現在のシーンを実行をすると、真っ赤な画面が実行されます。
実行後はシェーダーエディターから出力タブに切り替わります。シェーダーエディタータブをクリックするとシェーダーのコードが確認できます。
シェーダーエディターに戻す
コードの観察と実験
書いたコードは以下の通りです。
COLOR = vec4(1.0 ,0.0 ,0.0 ,1.0 );
COLORは色です。=は一般的なプログラミング言語 と同じく代入を意味しますので、右辺のvec4(1.0, 0.0, 0.0, 1.0)をCOLORに代入したということになります。
vec4は4つの要素を持つ4次元ベクトルです。コンピューターで色と言えばRGBが思い浮かびます。もう一つ値があるなら大抵はアルファ値、つまり透過値です。そこから推測すると、1つ目と4つ目が1.0で、2つ目と3つ目が0.0なので、赤が最大、緑と青がなしで、全く透過しない状態が予想できます。真っ赤になった結果と推測が一致します。
値を変更してさらに確認してみましょう。緑にしたければR=0, G=1, B=0, A=1にすればよいはずです。以下のように修正してみます。
COLOR = vec4(0.0 , 1.0 , 0.0 , 1.0 );
Ctrl + Sキーで保存すると緑色に変わりました。予想的中です!
緑色に変化!
他にも思いつく色を試してみましょう。青ならR=0, G=0, B=1、黄色ならR=1, G=1, B=0、水色ならR=0, G=1, B=1です。α値を0.5にすると色が薄くなることが確認できます。
画面の位置を色に反映させる
さきほどのコードは色を指定しただけで塗る場所を座標で指定しませんでした。ColorRect全体の色が変わったということは塗りつぶしの命令だったのでしょうか?
先ほどのコードを次のように変更します。
COLOR = vec4(UV.xy, 0.0 , 1.0 );
Ctrl+Sキーを押して保存するとカラフルになりました!
UVを指定
UVはCOLORと同じく、組み込み変数と呼ばれるGodotが自動的に用意してくれる変数です。組み込み変数や関数は便利なものが大量に用意されています。公式マニュアルにはシェーダーの種類ごとに使える組み込み変数や関数が記載されています。今回使っているのはシェーダーコードの1行目に書かれているcanvas_itemというシェーダーで、以下のページにリファレンスがあります。COLORやUVを探してみて下さい。
CanvasItemシェーダー — Godot Engine (4.x)の日本語のドキュメント
コードの観察と実験
コードは次の通りでした。
COLOR = vec4(UV.xy, 0.0 , 1.0 );
UV.xyとはなんでしょうか。公式ドキュメント で調べます。
UVの説明
UVのところには「頂点関数からのUV。」と書かれています。頂点関数はvertex()のことです。今回は実装を省略しているのでデフォルトの値が設定されたままfragment()に値が渡されます。
UVはテクスチャを貼り付ける位置を0から1の範囲で表した値です。描画された画像を見ると、左上が黒、右上が赤、左下が緑、右下が黄色です。これをRGBで表すと左上が0, 0, 0、右上が1, 0, 0、左下が0, 1, 0、右下が1, 1, 0ということになります。COLORに代入したのはvec4(UV.xy, 0.0, 1.0)でした。左上のUV値が0,0、右上が1, 0、左下が0, 1、右下が1, 1なら色と一致します。
ここで面白いのがUV.xyという書き方です。これはシェーダー言語でよく出てくる表現で、xとyの順の2次元ベクトルを表しています。CやC# ではこのような書き方はできませんが、シェーダーではベクトルを様々な方法で扱うので機能が拡張されているのです。例えば以下のようにxとyを入れ替えてみてください。
COLOR = vec4(UV.yx, 0.0 , 1.0 );
グラデーションの方向が変わる
グラデーションの色が縦横で入れ替わりました。他にもUV.xxやUV.yyのような書き方もできます。
fragment()の動き方
最初のコードはColorRectを一色で塗りつぶすだけでしたが、今回はグラデーションになりました。これはfragment()がColorRectで囲まれているすべてのピクセル ごとに実行されたからです。
UVには、ColorRectを構成する頂点からfragment()を実行するピクセル の位置に応じて、テクスチャーを貼り付けるための位置が線形補間されて渡されます。デフォルトでは小さい座標の頂点に0, 大きい座標の頂点に1が設定されるので、fragment()で描画する頂点の位置に応じて左上から右下に0から1の範囲でUV値が渡されます。それをCOLOR = vec4(UV.xy, 0.0, 1.0);でピクセル ごとに着色したのでグラデーションになったのです。
何か描きたいとき、通常は「どこに何を描画するか」を考えるのが自然です。それに対してフラグメントシェーダーでは 塗りつぶす面を構成するすべてのピクセル ごとに「そのピクセル を何色にするのか」 を考えます。
色を設定するために毎回シェーダーのコードを書き換えるのは面倒です。マテリアルで色を設定できるようにします。GodotではUniform入力 を使うことでマテリアルからシェーダーに値や素材を渡す ことができます。
シェーダーコードを以下のように書き換えてください。vertex()とlight()は使わないので消しました。
shader_type canvas_item;
uniform vec4 base_color : source_color = vec4(1.0 , 0.0 , 0.0 , 1.0 );
void fragment() {
COLOR = base_color;
}
保存するとColorRectが最初のコードのように赤一色になります。
赤に戻る
3行目のuniformから始まる行がUniform入力の定義です。vec4は既出の4次元ベクトルを表していて、base_colorが名前です。ここまでがUniform入力定義の必須項目です。これ以降はオプションの指定です。
source_colorはシェーダーヒントやHintと呼ばれるものです。Uniformや変数の特性を指定するために使います。Godotは色をLinear空間で扱います。画像ファイルや色指定はsRGBなのでそのままでは色がおかしくなるので、source_colorヒントをつけてsRGBからLinearに変換するように指定しています。その後ろは初期値でこの例では赤を指定しています。これも省略可能です。
色をマテリアルから変えてみましょう。
シーンでColorRectをクリックして選択します
ColorRectを選択
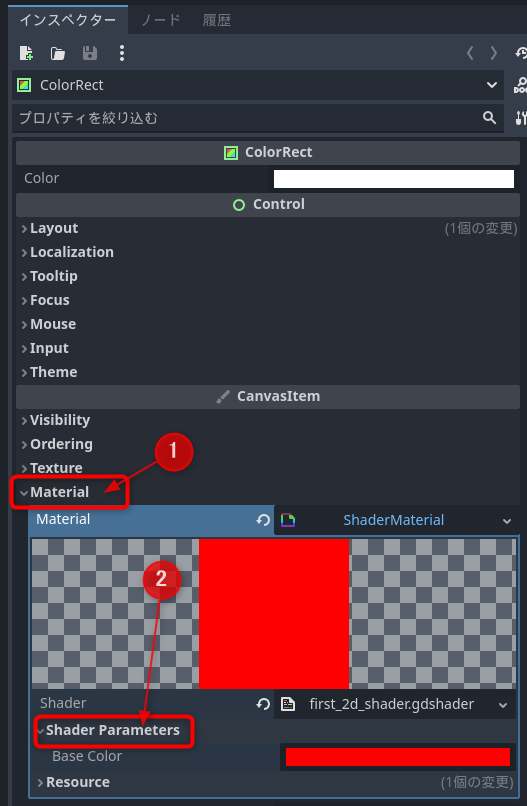
インスペクターのMaterial欄をクリックして、Shader Parameters欄をクリックします
MaterialのShader Parameters欄を開く
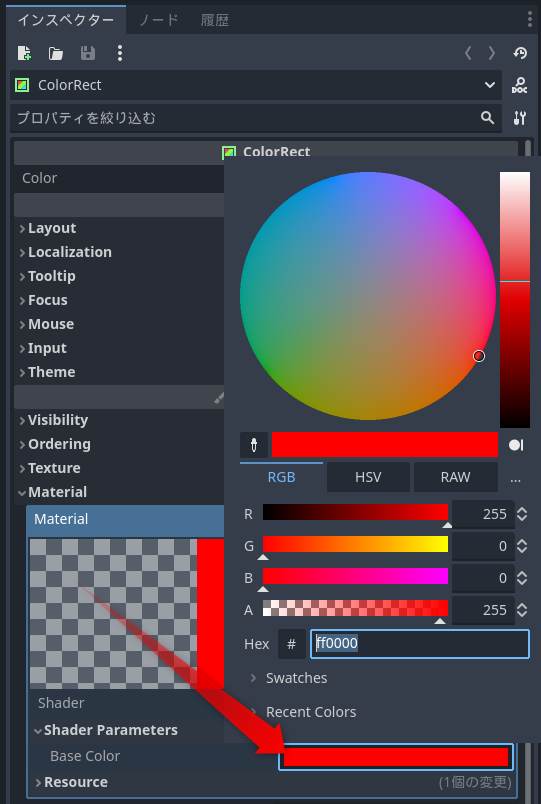
シェーダーに追加したbase_colorがBase Colorという名前で追加されています。Base Colorの色の四角をクリックするとカラーパネルが表示されます
カラーパネルを開く
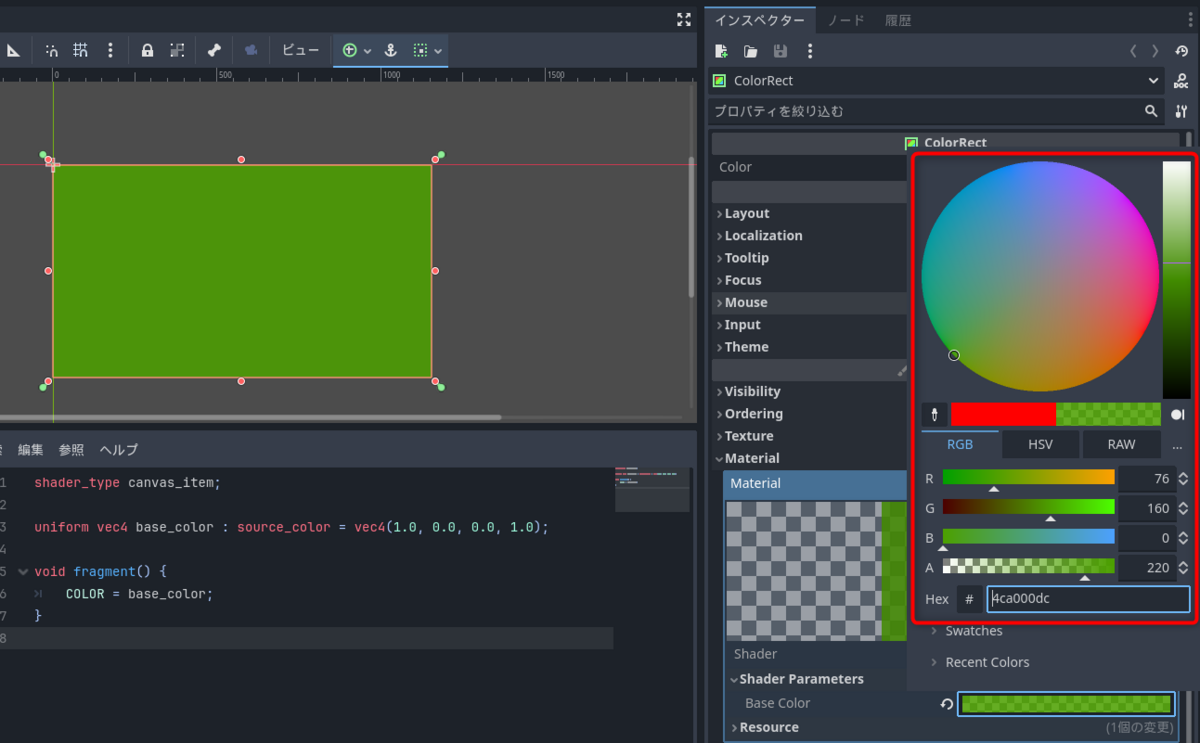
色やα値を変化させるとエディターのColorRectの色も変わるようになりました。
色をマテリアルから設定
Uniform入力ではさまざまなデータを設定することができます。詳しくはマニュアルの以下のページをご覧ください。
シェーディング言語 — Godot Engine (4.x)の日本語のドキュメント
COLORのデフォルトの色
ColorRectが最初に白くなるのは、デフォルトとしてインスペクターの一番上にあるColorが設定されるからです。
ColorRectのCOLORのデフォルトの色
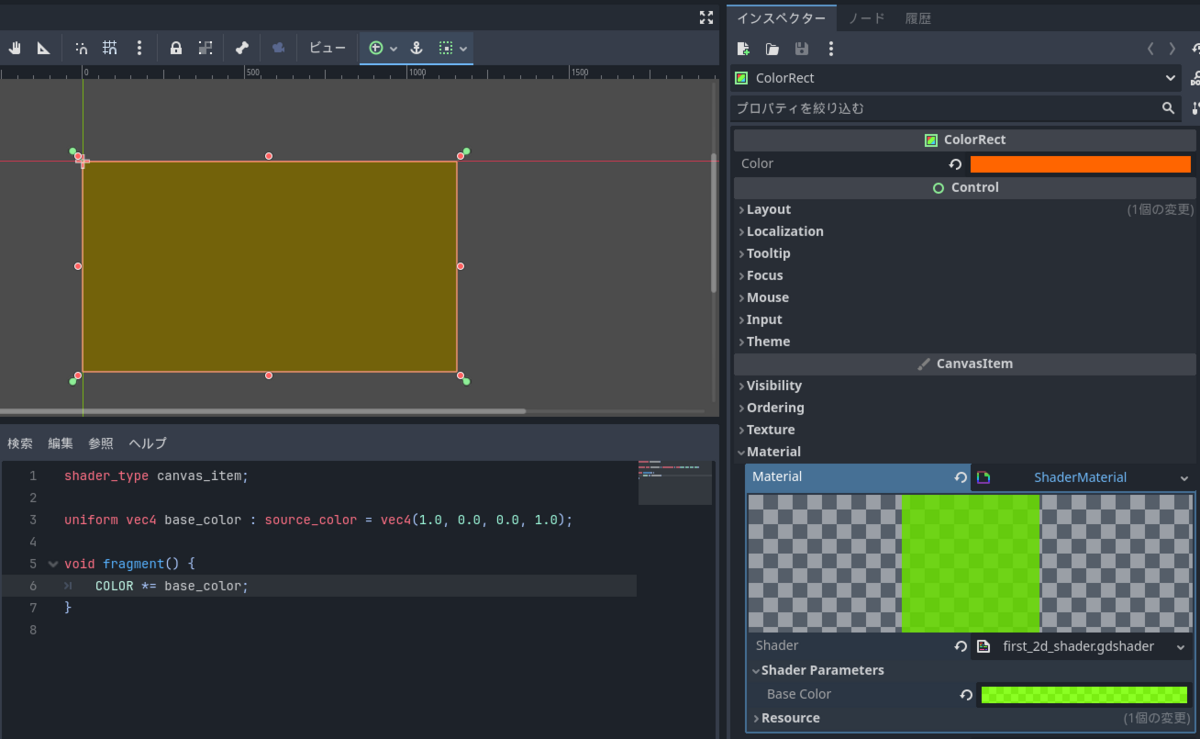
例えば以下のようにCOLORに色を掛ける式にすると、COLORとbase_colorの各要素を掛けた色になります。
COLOR *= base_color;
COLORの色を変えると、COLORとBaseColorのRGBの値をそれぞれ掛けた色になります。
オレンジ x 緑
マテリアルから画像を設定
画像を描画してみます。マテリアルで画像を設定するにはsampler2Dを使います。
uniform sampler2D image : source_color;
テクスチャ画像はsampler2D型で受け取ります。これも色のデータなのでsource_colorヒントをつけます。
テクスチャ画像から色を取り出すのは組み込み関数のtextureを使います。fragment()を以下のように書き換えます。
void fragment() {
COLOR *= texture(image, UV);
}
texture関数は、第一引数で取り出し元の画像、第2引数で読み取るUV座標を指定すると該当する場所の色を返します。これで設定した画像にCOLORの色を掛けた絵が描画されるようになります。画像は以下の手順で設定します。
シーンでColorRectをクリックして選択します
ColorRectを選択
インスペクターのShader Parameters欄のImage欄の空欄をクリックします
Imageをクリック
クイックロード
デフォルトでGodotアイコンのSVG ファイルが入っているので、選択して開きます
icon.svg を開く
設定できたらColorRectにGodotのアイコンが表示されます。プロパティのColorで色を変えると画像の色も変わります。
画像の描画
The Book of Shadersを試す
フラグメントシェーダーの雰囲気を味わいました。よりフラグメントシェーダーの理解を深めるために公式ドキュメントでも紹介されているThe Book of Shaders にあるいくつかのコードをGodotで動かしてみます。
グラフを描く
The Book of Shaders: Shaping functions にある数式のグラフを描くシェーダーをGodotで動かしてみます。新しいシェーダースクリプト に作成します。
シーンでColorRectをクリックして選択します
ColorRectを選択
インスペクターのMaterialにあるShader欄の右の下矢印をクリックして、新しいシェーダーをクリックします
新しいシェーダー
パスをalgorithmic_drawなどに変更して作成します
新しいシェーダーを作成
作成した新しいシェーダーを開く
shader_type canvas_item;
float plot(vec2 st, float pct){
return smoothstep( pct- 0.02 , pct, st.y) -
smoothstep( pct, pct+ 0.02 , st.y);
}
void fragment() {
float y = pow(UV.x, 5.0 );
vec3 color = vec3(y);
float pct = plot(UV, y);
color = (1.0 - pct)* color+ pct* vec3(0.0 ,1.0 ,0.0 );
COLOR = vec4(color, 1.0 );
}
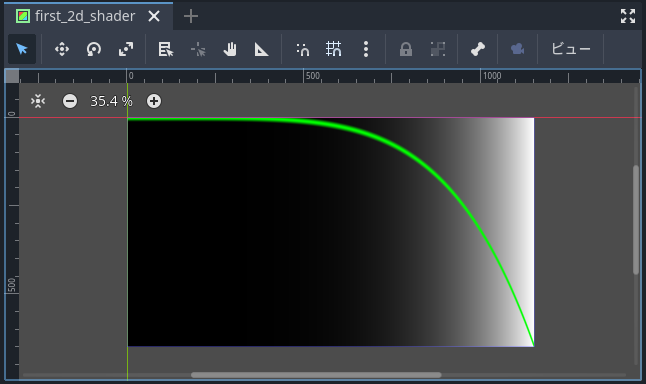
しばらく待つか保存すると記事のシェーダーが描画されます。
Expo
上下逆になっているのは、The Book of Shadersで動いている環境とGodotのColorRectでY軸の向きが逆だからです。
The Book of Shadersで紹介されているシェーダーのコードは少し手を加えれば動きます。以下、書き換えポイントです。
1行目にshader_typeを加える
4行目から12行目までのfloatの精度指定やPIなどの定義は不要なので削除
Godotのシェーダーでは以下のような組み込み変数が使えます
PIはPI
2PIはTAU
経過秒数はTIME
自然対数はE
stに算出しているピクセル の正規座標はUVに置き換えればよい
このコードでの10行目のyに、UV.xをXとして図形を描画する式を代入すればそれを描画します。例えばサインカーブ を時間で動かすなら以下のようにします。
float y = sin(UV.x* PI+ TIME)* 0.5 + 0.5 ;
動くSinカーブ
The Book of Shadersに紹介されているさまざまなグラフや色、表現を動かして理解を深めましょう。
その他の式
Algorithmic drawing に掲載されていたその他の式を以下に抜粋します。
float y = step(0.5 , UV.x);
float y = smoothstep(0.1 , 0.9 , UV.x);
float y = smoothstep(0.2 , 0.5 , UV.x) - smoothstep(0.5 , 0.8 , UV.x);
float y = mod(UV.x, 0.5 );
float y = fract(UV.x);
float y = ceil(UV.x);
float y = floor(UV.x);
float y = sign(UV.x);
float y = abs(UV.x);
float y = clamp(UV.x, 0.25 , 0.75 );
float y = min(0.5 , UV.x);
float y = max(0.5 , UV.x);
CellularNoise
最後にCellular Noise のページから見た目が面白いCellularNoiseの例の実行例です。これも新しくシェーダーを作るとよいかも知れません。
shader_type canvas_item;
vec2 random2( vec2 p ) {
return fract(sin(vec2(dot(p,vec2(127.1 ,311.7 )),dot(p,vec2(269.5 ,183.3 ))))* 43758.5453 );
}
void fragment() {
vec2 st = UV;
vec3 color = vec3(.0 );
st *= 3. ;
vec2 i_st = floor(st);
vec2 f_st = fract(st);
float m_dist = 1. ;
for (int y= - 1 ; y <= 1 ; y++ ) {
for (int x= - 1 ; x <= 1 ; x++ ) {
vec2 neighbor = vec2(float (x),float (y));
vec2 point = random2(i_st + neighbor);
point = 0.5 + 0.5 * sin(TIME + 6.2831 * point);
vec2 diff = neighbor + point - f_st;
float dist = length(diff);
m_dist = min(m_dist, dist);
}
}
color += m_dist;
color += 1. - step(.02 , m_dist);
color.r += step(.98 , f_st.x) + step(.98 , f_st.y);
COLOR = vec4(color,1.0 );
}
Cellular Noise
まとめ
Godotのインストールからシェーダーの作成をして、The Book of Shadersのサンプルをいくつか動かしてみました。試した印象としてはUnityのシェーダーより約束事が少なくてスムーズに動かすことができました。フラグメントシェーダーでグラフや形状を描く必要があるのか?と思われるかも知れませんが、基本を知っていればさまざまなエフェクトに応用できます。
ある程度の雰囲気が掴めたら、あらためて公式ドキュメントを読みこむとよいです。必要な情報がしっかりと解説されています。
docs.godotengine.org
今回は2Dで試しましたが3Dでも考え方は同じです。利用できる組み込み変数が増えたり、色を表すだけではなくなるので変数名が変わったりするので、適宜ドキュメントを参照することになりますが使いやすさは変わらないと思います。
以上、Godot Engineのカレンダー | Advent Calendar 2023 - Qiita の11日目の記事でした。
◆前の日は@NumAniCloud さんのC#プロジェクトを分割して開発しよう、の話 です。
◆次の日はきゃべつ さんのGodot(C#)シーン派生とクラス派生 #C# - Qiita です。
よいGodotライフを!
参考・関連URL